sphinx¶
文档的编写,是一个基础工作,从最初用的txt->sgml->docbook->markdown->restructureText,到后来的word,再到后来的wiki再到markdown,由于markdown的语法太简单,不能支持复杂的,并且通用性不强,见 此
格式要示。也就出现这三大工具:
- Creole 把各种wiki通用的语法总结成一个致语法,并且形成标准并制作相应的工具。
- SGML and XML docbook的语法太啰嗦。
- asciidoc a2x 相应的一堆转换工具类似rst.
- sphinx-doc 的rst.
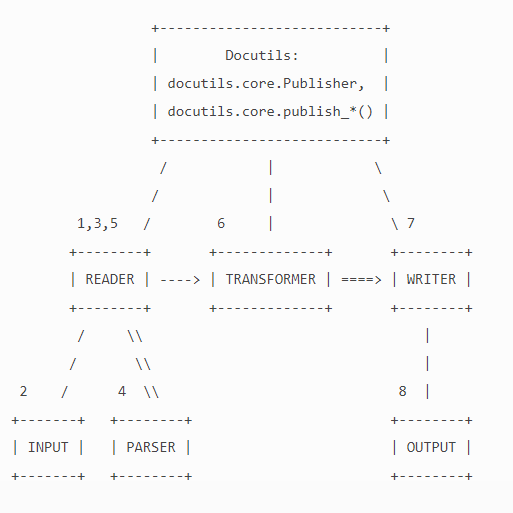
def publish(self,argv=None,usage=None,description=None,
settings_spec=None,settings_overrides=None,
config_section=None,enable_exit_status=False):
...
self.document = self.reader.read(self.source,self.parser,self.settings)
self.apply_transforms()
output = self.writer.write(self.document,self.destination)
publisher 的详细说明见 http://docutils.sourceforge.net/docs/api/publisher.html
parser 的原理¶
采用可以重入的状态机机制,其实也就是递归模式来进行解析,每一个node 都有startag,endtag.
- 从一个文档的开始定义一个document root.
- 从上到下进行逐行解析,同一级的每一个节点都是root的子节点顺序排列。
- 遇到子节点,进行递归进入当前节点的子节点。
root,
root.children=[.....]
chidren1
chidren[....]
chidren2
....
最后template rendering时,也是流式不断写文件是一样用content,或者body不断append内容。
template¶
sphinx 的模板用的是jinjia,类似于perl template toolkit,主要上下左右几部分,每一部分二次二次的代理,
例如sphinx 对整个分成了五部分
- doctype
- linktags
- extrahead 如果想独立的html可以把style 放在这里。
- rootrellink
- document 对于 body同时还一个page.html的模板。定义一下就个树了。其实也很简单。
例如就是封面,章,节等等。
{% extends "!layout.html" %}
{% set reldelim1 = '>' %}
{% block footer %} {% endblock %}
sphinx 能够实现的只用一个template engine都很容易实现。只要稍微把模板灵活一些,其实就搞定了。
各种template engine的对比 见 此
一个template engine应该具有的功能
- Variables
- Functions
- includes
- Condition inclusion
- Looping
- Evaluation
- Assignment
- Errors and exceptions
- il8n
- Natural templates
- Inheritance
class doc:
foreword = ""
chapters =[]
end=""
class chapter:
sections = []
titile = ""
foreach print anyformat
现在sphinx 已经把文档结构给解析好了。只需要实现reader 就行了。
而sphinx采用的是node 的机制。 http://sphinx-doc.org/latest/extdev/nodes.html 采用vistor 模式。这样也就是每节点类型,都会有一个自己的解析函数,每一个vistor 要实现自己需要处理的node. http://zh.wikipedia.org/wiki/%E8%AE%BF%E9%97%AE%E8%80%85%E6%A8%A1%E5%BC%8F
所以写builder也就容易了,reader已经把结构给读好了,我只要这些vistor方法实现一遍即可。 而在Visoter用的是 dispatch_vist(),walkabout 采用getattr的方法来判定这里是有由
默认的方法是原样copy,当然也可以skipNode. 可以这样的丰富。
vist_... 的方法, 在writers/html.py里面是一目了然。writer 就像包管理中的dpkg,而builder 就像是apt-get.
中间的连接用的是 publish pattern, pub.reader,以及pub.writer的方法。
http://docutils.sf.net/docs/api/publisher.html
从这里就可以看publish_parts 就看协议包的构造了,如何来构造了。并且每一块对应关系就有了。只要把流程搞明白了,如何实现采用什么样的pattern是自然而然的事情。
http://docutils.sourceforge.net/docs/peps/pep-0258.html
而整个sphinx 是建立在docutils 的基础上的。
并且http://www.arnebrodowski.de/blog/write-your-own-restructuredtext-writer.html
哈哈,原来那些unit 测试都是采用这样的方法的设计的,采用vistor模式。
那些继承是为了正方便修改。只改需要修改的问题。
doctree 本身的扩展有三种: #. role 一种简单的inline element. #. directive 这种类类似于 graphviz 插件。 #. transform 也就是添加过滤器。有点类似于LLVM 的Pass. #. output本身的格式化,例如html,还有template + css 可以用。
设计方法很简单
import test
clslist = getclstst(test)
for cls in clslist:
name = cls.__class_.__name__
setup = getattr(cls,"setup__")
run = getattr(cls,"run__")
close = getattr(cls,"close__")
print "begin testing {}" %(name)
print " setup: {} " %(name)
setup()
print " run:{} " %(name)
run()
close()
print " finish{} " %(name)
而sphinx 的内部结构可以http://docutils.sourceforge.net/docs/ref/docutils.dtd 这时得到,同时对应,docutils/nodes.py就可以了。
其被背后用是https://docs.python.org/2/library/xml.dom.minidom.html,其实起来了也很简单。 其整个的实现方法,那就在nodes.py里,每一个节点就是一个tag,并且都会指定自己的accept方法。
都每个都有startag,以及endtag. http://docutils.sourceforge.net/docs/ref/doctree.html
transform¶
基本上是进来node列表,出来一个node列表。
for ref in self.document.traverse(nodes.substuition_reference):
refname = ref['refname']
"""
do something
"""
ref.replace_self(nodes.Text(text,text))
toc tree¶
直接用 toc来得到这个tree,同时可以用node.pformat,node.asdom().toxml()就可以生成生了。
singlehtml¶
对于sphinx现在没有办法方便做到,singlehtml重新写一个新的builder,不过也应该不是很难。 一个简单的办法,利用模板 直接把需要东东都放在 header. 例如把样式表放在前面。 然后所有需要放东东都放在style.css中就行了。
http://www.sphinx-doc.org/en/stable/extdev/nodes.html 可以这些api.
{% extends "!layout.html" %}
{% set reldelim1 = '>' %}
{% block extraheader %}
{% include "../_static/sytle.css %}
{% endblock %}
生成pdf¶
默认的documentclass只有两种 howto,manual, 或者自定义,没有也行 但如果title 指定了中文,同时指定了manual就报错了,应该是manual对中文的支持不够。
添加对文献的支持用 bibtex 参考 http://sphinxcontrib-bibtex.readthedocs.org/en/latest/usage.html。 现在的问题是添加文献,没有索引号,但是第一版是可以的,看看是哪里配置做了。
sphinx 进行二次开发¶
http://sphinx-doc.org/extdev/tutorial.html#exttut http://docutils.sourceforge.net/docs/ref/doctree.html
http://sphinx-doc.org/extdev/nodes.html#nodes
内部结构的存储,用node的链表
如何添加一个role¶
可以参考这个 https://doughellmann.com/blog/2010/05/09/defining-custom-roles-in-sphinx/
主要是两步
注册你的role
def setup(app): """Install the plugin. :param app: Sphinx applicaton context. """ app.add_role("fb",fb_role) return
写你自己的回调函数
def fb_role(name,rawtext,text,lineno,inliner,options,content): node = make_a_node(...) return [node], []
更进一步的定制可以参考 Docutils Hacker’s Guide
rst 本身的解析采用的是状态机来实现的,具体的实现可以参考 /usr/local/lib/python2.7/dist-packages/docutils/parsers/rst/states.py
单个文本的转换,可以用http://docutils.sourceforge.net/docs/api/cmdline-tool.html 这些实现,当然也可以采用pandoc来实现。
标题的层级¶
sphinx本身没有特殊符号要求,默认遇到的第一个是就一级level. 你只要保证使用的一致就行了。 但是当文件太大,使用了各种include在一起的时候,就可能会有各种不一致。
如何在readthedoc上添加一个留言区¶
可以参考 https://github.com/moorepants/dissertation/blob/master/_templates/page.html 原理就是在模板中加入的`Disqus <https://disqus.com/>`_ ,或者自己搭一个`isso <https://github.com/posativ/isso>`_ 的comments server. 并且添加额外的javascript 来实现它,如何添加额外的js可以参考 how-to-load-external-javascript-in-sphinx-doc
以及如何用sphinx来写论文,可以参考 https://github.com/moorepants/dissertation 以及如何用sphinx来写书,可以参考http://hyry.dip.jp/tech/book/page.html/sphinx/index.html, Python科学计算 就是用 Sphinx来写的。
条件包含¶
可以采用 https://stackoverflow.com/questions/15001888/conditional-toctree-in-sphinx,也可以在 conf.py里添加代码直接发生成 或者可以事件生成部分内容,然后把加进正式的编译中。 Including content based on tags 这个类似于C的#IFDEFINE
当然sphinx也是支持tag来实现条件包含编译的。 https://stackoverflow.com/questions/16863444/conditionally-include-extensions
用代码生成文档¶
https://stackoverflow.com/questions/7250659/python-code-to-generate-part-of-sphinx-documentation-is-it-possible 用上面的方法也行,也可以用ptyhon 相应的 tabulate , rstcloth 当然可以用插件transform来完成。
各种rst的工具¶
https://stackoverflow.com/questions/2746692/restructuredtext-tool-support/2747041#2747041
最基本的工具:
- rst2html
- from reStructuredText to HTML
- rst2xml
- from reStructuredText to XML
- rst2latex
- from reStructuredText to LaTeX
- rst2odt
- from reStructuredText to ODF Text (word processor) document.
- rst2s5
- from reStructuredText to S5, a Simple Standards-based Slide Show System
- rst2man
- from reStructuredText to Man page